Den passenden Ansatz finden: Studienplanung als erster Schritt zur Beantwortung Ihrer Forschungsfrage
Die Wissenschaft der Daten verstehen
Dieser Artikel wurde in MedinLux veröffentlicht und ist Teil einer gemeinsamen Anstrengung, statistische und epidemiologische Konzepte den Angehörigen der Gesundheitsberufe in Luxemburg zugänglich zu machen.
Jede Studie beantwortet eine spezifische Frage. Diese Frage spielt eine wesentliche Rolle bei der Auswahl des Studientyps, der wiederum die durchzuführenden statistischen Analysen bestimmt. Diese Analysen sollten frühzeitig festgelegt werden (noch bevor die Daten vorliegen, um nicht durch diese beeinflusst zu werden; siehe Artikel über den p-Wert). In diesem Artikel stellen wir Ihnen verschiedene Studientypen vor, die Ihnen dabei helfen, Ihre Forschungsfrage besser zu beantworten, sowie deren Vor- und Nachteile. Der Studientyp variiert je nach Forschungsziel: Geht es darum, den Zusammenhang zwischen einer Exposition und einer Krankheit zu untersuchen, sind experimentelle Studien am geeignetsten. Möchte man hingegen eine Krankheit oder ein Ereignis in Bezug auf
einen Ort, eine Zeitspanne oder eine spezifische Bevölkerung beschreiben, sind Beobachtungsstudien besser geeignet
EINGREIFEN, UM ZU BEWERTEN
Experimentelle Studien, insbesondere randomisierte klinische Studien, haben das Ziel, die Wirksamkeit einer neuen Behandlung (sei es ein Gerät oder ein Medikament) zu bewerten, indem diese in der Regel mit einem Placebo oder einer Referenzintervention verglichen wird. Die Zuteilung der Teilnehmer zu den Interventionen erfolgt zufällig (Randomisierung).
Ein Merkmal dieser Studien ist die Zuteilung der Teilnehmer. Je nach Typ unterscheidet sich die Behandlungszuweisung. Es gibt zahlreiche Designs: Das am häufigsten verwendete ist die Parallelgruppen-Studie. Die Teilnehmer werden zufällig einer Gruppe zugeteilt, wobei manchmal darauf geachtet wird, dass die Gruppen ähnliche Merkmale aufweisen (z. B. das gleiche Durchschnittsalter, der gleiche Anteil von Männern und Frauen, die gleiche Verteilung der Krankheitsschwere). Die Gruppen werden gleichzeitig und unabhängig voneinander beobachtet.
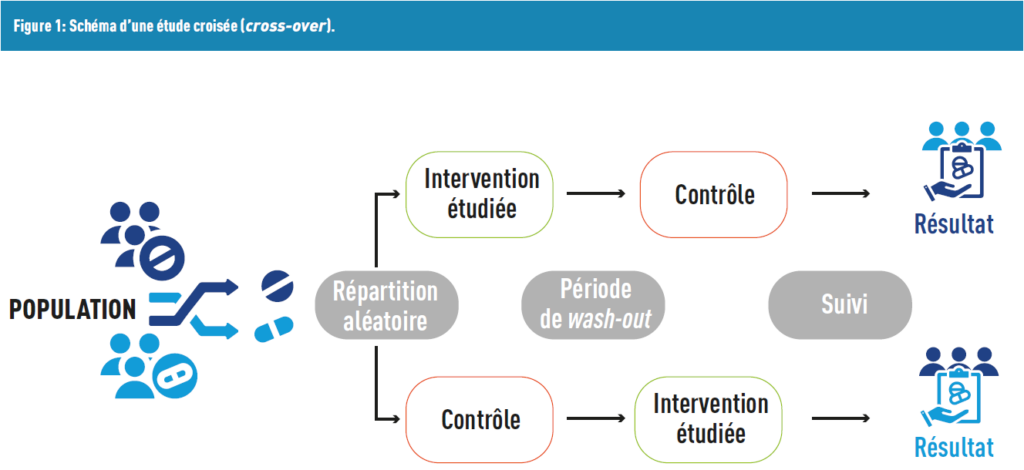
Ein anderer Design-Typ sind Crossover-Studien, bei denen jeder Teilnehmer seine eigene Kontrollgruppe darstellt. In diesem Studiendesign erhalten die Teilnehmer zunächst eine Behandlung, gefolgt von einer Washout-Periode, in der keine Behandlung erfolgt, um die Wirkung der ersten Behandlung zu eliminieren. Schließlich erhalten die Teilnehmer die andere Behandlung, die sie in der ersten Periode nicht hatten (Abbildung 1).
Diese Liste ist nicht abschließend: Es gibt weitere innovative und komplexe Ansätze wie Basket-, Umbrella-, Adaptive- oder Plattform-Studien. Ihre Beschreibung geht jedoch über den Rahmen dieses Artikels hinaus.
Die Gruppenzuteilung kann einfach verblindet (nur die Teilnehmer wissen nicht, ob sie das Placebo/die Referenzbehandlung oder die neue Behandlung erhalten) oder doppelblind sein (weder die Teilnehmer noch das medizinische Personal kennen die Details der Behandlung). Dies begrenzt den Placebo-Effekt, der als wahrgenommene Verbesserung (oder Verschlechterung) durch den Teilnehmer, ohne die Einnahme aktiver Wirkstoffe im Behandlungsprozess, definiert wird.
Randomisierte klinische Studien gelten als Goldstandard für Evidenz und Kausalität, da viele Faktoren kontrolliert werden. Allerdings erfordern diese Studien viel Zeit und Budget.
HINWEIS DER BIOSTATISTIKERIN
Die Daten können wie folgt analysiert werden:
– Intention-to-Treat (ITT): Randomisierte Teilnehmer werden in die Analyse einbezogen, auch wenn sie die ursprünglich geplante Behandlung nicht vollständig durchgeführt haben. Die ITT-Analyse zielt darauf ab, Verzerrungen in der Interventionsforschung zu vermeiden, wie z. B. nicht-randomisierte Abbrecher oder Wechsel zwischen Behandlungsgruppen. Diese Methode wird von den Consolidated Standards of Reporting Trials (CONSORT) empfohlen. Ein Kritikpunkt dieser Analyse ist jedoch, dass sie konservativ ist und somit anfälliger für Fehler des Typs II (siehe Artikel über den p-Wert)
– Per-Protokoll-Analyse: Teilnehmer, die vom Protokoll abgewichen sind, werden ausgeschlossen. Dies ermöglicht die Schätzung der maximalen Wirkung der Behandlung. Aufgrund von Abbrüchen (z. B. wegen Unwirksamkeit oder Nebenwirkungen) ist die Gesamtzahl der Teilnehmer jedoch geringer als geplant, was zu einer geringeren statistischen Power führt. Eine Stichprobenberechnung ist erforderlich, um dieses Problem zu lösen. Die Vorteile der Randomisierung gehen verloren, und die Gruppen könnten unausgewogen sein. Außerdem entspricht dies nicht den Bedingungen des realen Lebens, in dem Patienten ihre Verschreibungen oft nicht strikt einhalten.
BEOBACHTEN, UM BESSER ZU VERSTEHEN
Wie bereits erwähnt, zeichnen sich Beobachtungsstudien dadurch aus, dass sie nicht aktiv in die untersuchte Population eingreifen. Sie befassen sich mit der Wirkung eines Risikofaktors, eines diagnostischen Tests oder einer Behandlung, ohne die Exposition zu beeinflussen. Diese Studien lassen sich in zwei Kategorien unterteilen: deskriptive Studien und ätiologische Studien.
EINEN ÜBERBLICK GEWINNEN
In deskriptiven Studien geht es darum, Gesundheitsphänomene innerhalb einer Population zu beschreiben. Diese Studien konzentrieren sich auf die Beschreibung von Trends und Merkmalen der untersuchten Population. Allerdings können sie keine Ursache-Wirkungs-Beziehungen herstellen oder die Gründe für das Phänomen erklären. Ein einfaches Beispiel ist die Untersuchung der Anzahl von Grippefällen im Winter 2023–24 in Luxemburg.
Unter den deskriptiven Studien analysieren Querschnittsstudien (Cross-Sectional-Studien) eine oder mehrere Populationen zu einem bestimmten Zeitpunkt. Diese Methode liefert eine Prävalenzschätzung, d. h. das Verhältnis der Personen mit einer bestimmten Krankheit zur Gesamtbevölkerung, häufig ausgedrückt pro 10.000 oder 100.000 Personen, ohne zwischen neuen und bestehenden Fällen zu unterscheiden. Die Stichprobe muss repräsentativ für die Zielpopulation sein, um eine unverzerrte Prävalenzschätzung zu gewährleisten. Diese Methode kann mit einer Momentaufnahme der beobachteten Population verglichen werden, wie beispielsweise bei der European Health Interview Survey (EHIS) [1], die von der Europäischen Kommission durchgeführt wird.
Ein weiteres Beispiel sind ökologische Studien, die einen breiteren Rahmen haben. Hier sind die Analyseobjekte Gruppen (Städte, Regionen oder Länder), während sich die zuvor erwähnten Studien auf Individuen konzentrieren, die Teil von Gruppen sind. In ökologischen Studien werden aggregierte Daten aus externen Quellen verwendet, sodass keine Daten auf individueller Ebene verfügbar sind. Diese Studien sind relativ einfach, schnell und kostengünstig durchzuführen, da meist bereits vorhandene Daten genutzt werden. Sie dienen dazu, den Weg für robustere Kohorten- oder Fall-Kontroll-Studien zu ebnen, welche weniger anfällig für Verzerrungen sind, indem sie interessante Zusammenhänge aufdecken. Ein historisches Beispiel ist die Untersuchung der Cholera-Epidemie in London durch John Snow, bei der er die Fälle auf Stadtviertel verteilte. Diese Studie markierte den Beginn der modernen Epidemiologie, mit der Einführung von verschiedenen Konzepten wie der Inzidenz (Anzahl neuer Krankheitsfälle in einem bestimmten Zeitraum).
GRUPPEN VERGLEICHEN
Ätiologische Studien zielen darauf ab, Verbindungen zwischen verschiedenen Faktoren (Umwelt-, genetische oder Verhaltensfaktoren) und dem Auftreten von Krankheiten herzustellen. Im Gegensatz zu Interventionsstudien ist die Kontrolle bestimmter Faktoren nicht möglich. Eine der größten Einschränkungen von Beobachtungsstudien ist das Vorhandensein von Verzerrungen, die schwer zu kontrollieren sind. Die auffälligste ist die Selektionsverzerrung, die entsteht, wenn die untersuchte Population nicht repräsentativ für die Zielpopulation ist. Allerdings ist die Liste der Verzerrungen lang (z. B. Verwechslung, Messungen, Informationen…) und wird in einem zukünftigen Artikel erklärt!
FALL-KONTROLL-STUDIEN
Bei Fall-Kontroll-Studien werden zwei Gruppen unterschieden: Die erste besteht aus Personen mit dem Gesundheitsproblem (Fälle), während die zweite Gruppe ohne dieses Problem als Kontrollgruppe (Kontrollen) bezeichnet wird. Die Personen der Kontrollgruppe weisen ähnliche Merkmale (z. B. Alter, Geschlecht) wie die der Patientengruppe auf. Durch diese Gruppenzuordnung wird die individuelle Variabilität reduziert. Dieses Design wird häufig bei seltenen Krankheiten verwendet.
KOHORTENSTUDIEN
Kohortenstudien eignen sich, wenn Forscher an einer definierten Population interessiert sind, die unterschiedliche Expositionsniveaus gegenüber Risikofaktoren aufweist, wie z. B. Arbeiter (Population), die eine Maschine verwenden (oder nicht), die giftige Gase abgibt (Risikofaktor). Diese Studien sind besonders nützlich zur Analyse von Krankheiten mit kurzer Inkubationszeit, chronischen Erkrankungen mit mehreren Stadien oder relativ häufigen Krankheiten. Sie können spezialisiert sein (kleine Stichproben, hochspezifische Probleme, detaillierte Daten) oder allgemeiner (große Stichproben, breite Abdeckung von Gesundheitsproblemen, weniger detaillierte Daten). Außerdem können sie als Grundlage für weiterführende Forschungen dienen, wie z. B. das CLINNOVA-Projekt, an dem das Luxembourg Institute of Health (LIH) beteiligt ist. Dieses Projekt sammelt Daten aus mehreren europäischen Kohorten, um mithilfe künstlicher Intelligenz die Behandlung von drei entzündlichen Erkrankungen (Darm, rheumatoide Arthritis, Multiple Sklerose) zu verbessern.
VOR ODER NACH DEM AUFTRETEN DER KRANKHEIT?
Eine weitere wichtige Frage ist der Zeitpunkt, an dem die Population untersucht werden soll: Soll dies vor oder nach dem Auftreten der Krankheit geschehen?
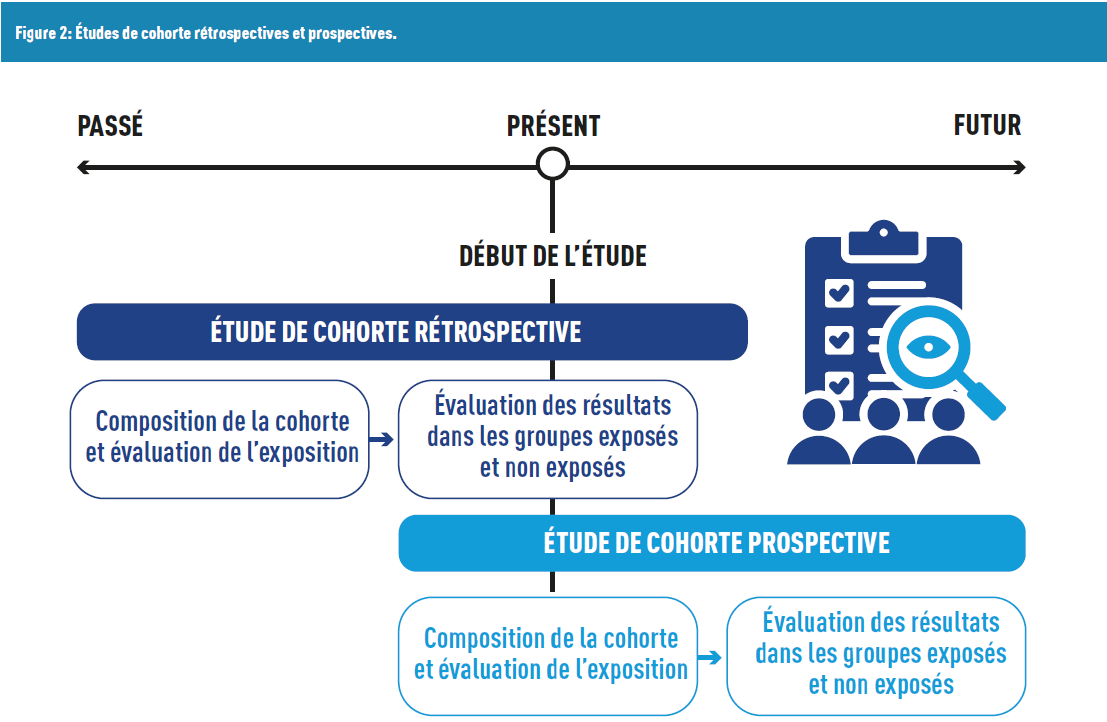
Im ersten Fall handelt es sich um retrospektive Studien, bei denen die Teilnehmer die Krankheit bereits haben und die Forscher „in die Vergangenheit blicken“, um Expositionen oder potenzielle Risikofaktoren zu identifizieren. Eine Einschränkung dieser Methode ist der Erinnerungsbias: Die Teilnehmer könnten Schwierigkeiten haben, sich an vergangene Expositionen zu erinnern. Dieser Bias kann minimiert werden, wenn medizinische Unterlagen zugänglich sind und deren Daten integriert werden können (mit Zustimmung der Teilnehmer, insbesondere zur Einhaltung der Datenschutz-Grundverordnung (DSGVO)).
Im zweiten Fall handelt es sich um prospektive Studien, die darauf abzielen, Risikofaktoren zu identifizieren, um das zukünftige Auftreten (oder Nicht-Auftreten) einer Krankheit vorherzusagen. Diese Studien haben eine zukunftsorientierte zeitliche Struktur. Sie sind kostspieliger aufgrund ihrer Dauer (wenn die Teilnehmer beobachtet werden, bis sie die Krankheit entwickeln).
DEN GLEICHEN TEILNEHMER MEHRFACH MESSEN ODER VERSCHIEDENE TEILNEHMER NUR EINMAL?
Zu den Beobachtungsstudien gehören longitudinale Studien (auch Panelstudien genannt), bei denen dieselbe Population über einen längeren Zeitraum hinweg beobachtet wird. Dies kann sich über mehrere Tage, Monate, Jahre oder Jahrzehnte erstrecken, je nach den interessierenden Risikofaktoren. Ziel ist es, Veränderungen bei den Teilnehmern zu erkennen und den Zusammenhang zwischen bekannten oder vermuteten Expositionen und dem Auftreten von Krankheiten zu untersuchen. Eine der frühesten und bekanntesten longitudinalen Studien ist die Framingham-Studie, die 1948 in den USA begann und sich mit kardiovaskulären Erkrankungen und deren Determinanten befasste.
Es ist wichtig, die Daten aus longitudinalen Studien nicht mit Daten aus wiederholten Querschnittsstudien zu verwechseln. In letzteren werden wiederholt Messungen an verschiedenen Personen durchgeführt, während in ersteren dieselben Personen über einen längeren Zeitraum hinweg verfolgt werden.
WIE KÖNNEN STUDIEN BEWERTET WERDEN?
In der klinischen Praxis können Entscheidungen auf mehrere Arten getroffen werden (definiert von Isaacs und Fitzgerald [3]):
- Tradition: Sie haben den Patienten mit dieser Pathologie immer diese Behandlung verschrieben,
- Erfahrung: Seit Beginn Ihrer beruflichen Laufbahn haben Sie beobachtet, dass diese Behandlung besser wirkt,
- Expertenmeinung (Eminence-Based Medicine): Sie haben einen anerkannten Spezialisten zu Rate gezogen und vertrauen auf dessen Ratschläge,
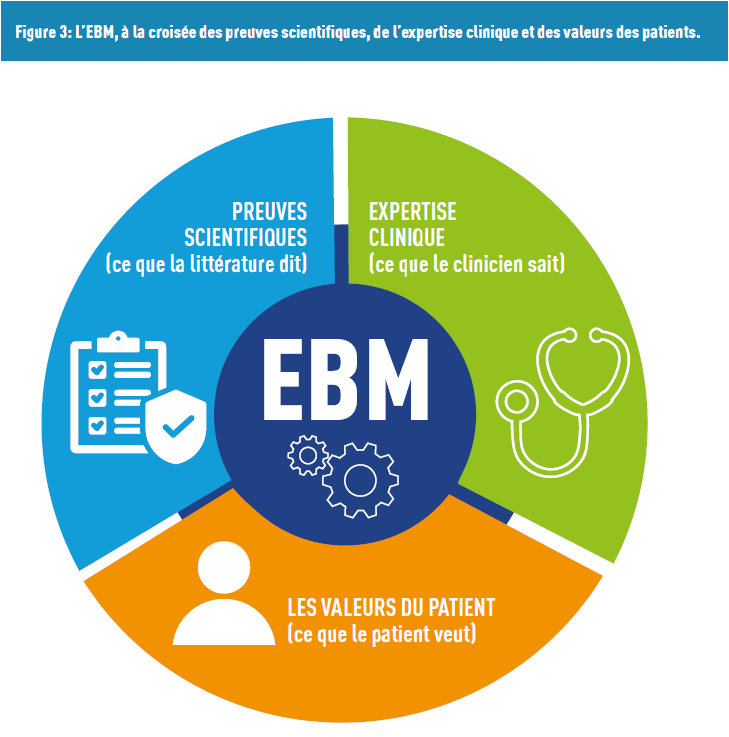
Diese Ansätze werden häufig der Evidenzbasierten Medizin (EBM) gegenübergestellt. Dieses Konzept, das in den 1950er Jahren entstand, kombiniert Prinzipien und Methoden und berücksichtigt dabei die Expertise des Arztes, die Fortschritte der Forschung und die Werte des Patienten (Abbildung 3).
In diesem Zusammenhang haben Informationen aus der wissenschaftlichen Literatur nicht denselben Evidenzgrad. Es gibt verschiedene Methoden zur Bewertung dieser Studien.
Erstens wird das GRADE-Tool (Grading of Recommendations Assessment, Development and Evaluation) von über 100 Organisationen weltweit verwendet, um die Qualität von Studien zu bewerten und Empfehlungen abzugeben. Die Evidenzstufen reichen von „sehr niedrig“ (der tatsächliche Effekt unterscheidet sich wahrscheinlich stark vom geschätzten Effekt) bis „hoch“ (die Autoren sind sich sicher, dass der geschätzte Effekt dem tatsächlichen Effekt sehr nahe kommt). Diese Skala basiert auf mehreren Kriterien wie Verzerrungsrisiko, Ungenauigkeit oder mangelnder Konsistenz (mit bestehenden Studien).
Zweitens wurden Evidenzstufen entwickelt, die von der wissenschaftlichen Gemeinschaft und vielen Institutionen (Weltgesundheitsorganisation, Haute Autorité de Santé usw.) unterstützt werden. Die niedrigste Stufe ist die Expertenmeinung, gefolgt von Fallserien (oder Fallberichten), da diese nur eine geringe Anzahl von Personen betreffen und ihre Schlussfolgerungen schwer auf größere Populationen übertragbar sind. Im Gegensatz dazu gehören Meta-Analysen zur höchsten Evidenzstufe. Dies ist eine statistische Forschungsmethode, die die Analysen mehrerer Studien zu demselben Thema kombiniert.
Die erste Phase dieser Methode besteht darin, eine systematische Literaturübersicht mit vordefinierten Kriterien durchzuführen und die relevanten Informationen aus jedem ausgewählten Artikel zu extrahieren. In der letzten Phase wird eine Gesamtschätzung des Effekts ermittelt, wobei die Heterogenität der Studien berücksichtigt wird, die oft durch Forest-Plots dargestellt wird (Abbildung 4).
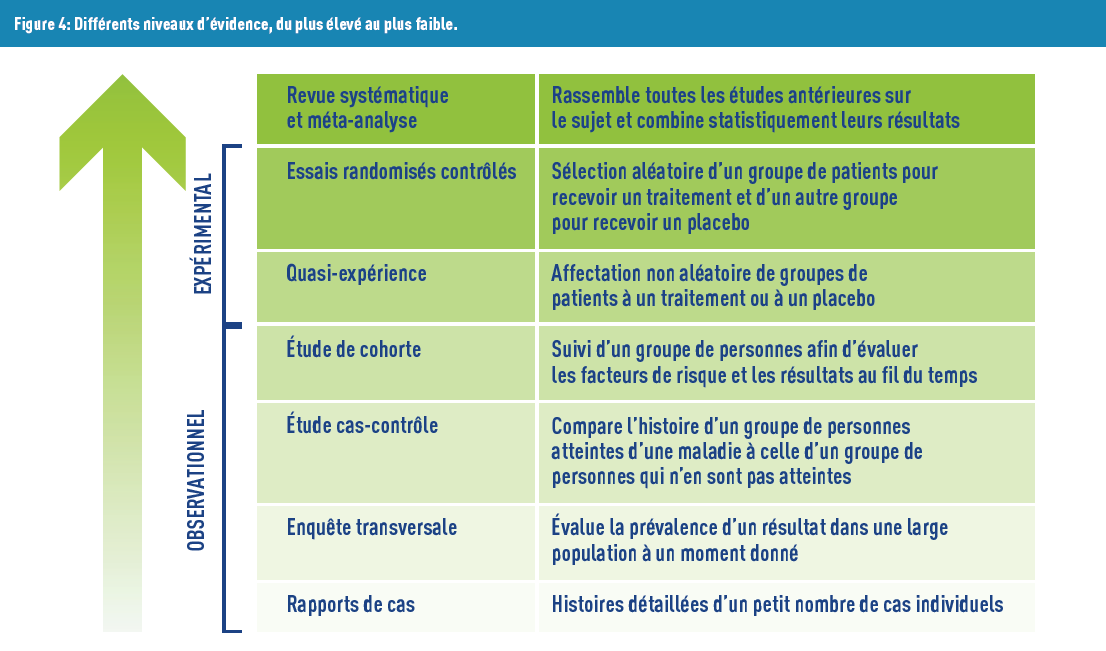
Aber jedes Tool hat seine Kritikpunkte. Einerseits gibt es den Publikationsbias, bei dem nur Studien mit „interessanten“ Ergebnissen veröffentlicht und somit zugänglich sind. Dieser Bias wirkt sich auf Meta-Analysen (unter anderem) aus, da sie mehrere Studien kombinieren.
Andererseits werden randomisierte klinische Studien als Goldstandard für Evidenz angesehen. Obwohl sie Patienten mit nur einer einzigen, sorgfältig ausgewählten Pathologie betreffen, kann es schwierig sein, die Ergebnisse auf andere Populationen zu übertragen! Dieses Problem ist besonders bei älteren Patienten relevant, die oft in Studien unterrepräsentiert sind. Allerdings werden zunehmend geriatrische Studien durchgeführt, um Behandlungen in Kombination mit den Multimorbiditäten dieser Patienten zu testen
ES GEHT NICHT NUR UM ZAHLEN!
Darüber hinaus berücksichtigt diese Zusammenfassung nur Studien, die Phänomene quantifizieren, obwohl es auch qualitative Studien gibt. Diese basieren in der Regel auf Fokusgruppen oder Einzelinterviews mit einer begrenzten Anzahl von Teilnehmern (DELPHI-Methode). Diese Methode hilft, die Erfahrungen, Wahrnehmungen und Verhaltensweisen der Teilnehmer zu verstehen. Ihre Vorteile sind Flexibilität und die Generierung neuer Ideen. Andererseits sind die Informationen subjektiv, stammen aus kleinen Stichproben (was eine Verallgemeinerung auf größere Populationen erschwert) und sind daher nicht reproduzierbar.
Sobald Sie den Studientyp ausgewählt haben, der Ihre Forschungsfrage beantwortet, ermöglicht die Berechnung der Stichprobengröße (oder Power), dass Ihre Studie ausreichend „Stärke“ besitzt, um valide Ergebnisse zu liefern (siehe vorheriger Artikel über den p-Wert).
Im nächsten Artikel werden wir die Konzepte von Assoziation und Kausalität untersuchen. Zögern Sie nicht, uns Ihre Fragen zu spezifischen epidemiologischen oder statistischen Themen zuzusenden, die wir in zukünftigen Artikeln beantworten werden.
KERNPUNKTE
Die folgende Tabelle fasst die im Artikel erläuterten Konzepte zusammen.
| GESTELLTE FRAGE | STUDIENTYP |
|---|---|
| Kann Test X Lungenkrebs effektiver erkennen als Test Y? | Randomisierte Studie |
| Wie hoch ist die Inzidenz von Lungenkrebs in Luxemburg? | Kohortenstudie |
| Wie hoch ist die Prävalenz von Lungenkrebs bei Rauchern? | Querschnittsstudie |
| Haben Menschen, die Passivrauchen ausgesetzt sind, ein höheres Risiko, Lungenkrebs zu entwickeln? | Fall-Kontroll-Studie, Kohortenstudie |
| Wie nehmen Patienten mit Lungenkrebs ihre Behandlung wahr? | Qualitative Studie |
Réferences
- 1. https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Glossary:European_health_interview_survey_(EHIS)
- 2. https://www.lih.lu/fr/article/clinnova-lance-une-initiative-de-medecine-de-precision-au-coeur-de-leurope/
- 3. https://www.bmj.com/content/319/7225/1618
- 4. https://gdt.gradepro.org/app/handbook/handbook.html
Die in MEDINLUX veröffentlichten epidemiostatistischen Reihen.
Ähnliche News