News
Statistical Bias: An Undesirable Effect on Data
Understanding the science of data
This article was published in MedinLux and is part of a collaborative effort to make statistical and epidemiological concepts accessible to healthcare professionals in Luxembourg.
Clinical studies are the cornerstone of evidence-based medicine. However, their validity can be compromised by the presence of biases — systematic errors that distort the estimation of results. Whether they occur during participant selection, data collection, analysis, or even after publication, biases can lead to deceptive conclusions and ultimately influence medical practice. Acknowledging their existence, avoiding them as much as possible, and accounting for them when interpreting results are essential steps for strengthening the quality of scientific research and ensuring the relevance of the resulting clinical decisions.
Introduction
The reliability of clinical studies depends on their ability to reflect reality. However, this requirement is undermined by biases — systematic errors that shift results away from reality in a particular direction. Unlike random errors, which represent inherent but neutral variability, biases compromise internal validity, meaning the credibility of conclusions drawn within the study population itself, as well as external validity, that is, the ability to generalize these results to other populations or contexts.
Thus, a study may appear coherent in its conduct, but if its participants are not representative of the target population or if measurements are distorted, its conclusions lose their practical relevance. Recognizing and minimizing bias is therefore a key challenge – at the stage of study design, during the analysis and interpretation of published results. No clinical trial is entirely free from biases, but identifying those and accounting for them helps to improve the reliability of conclusions and strengthen the value of data-driven medical decisions.
CLEARLY DISTINGUISHING BIAS FROM RANDOM ERROR
Potential bias already arises as soon as sampling takes place. In practice, it is rarely possible to study the entire population because of time and/or budget constraints. Therefore, a selected sample should best reflect the target population (Figure 1).
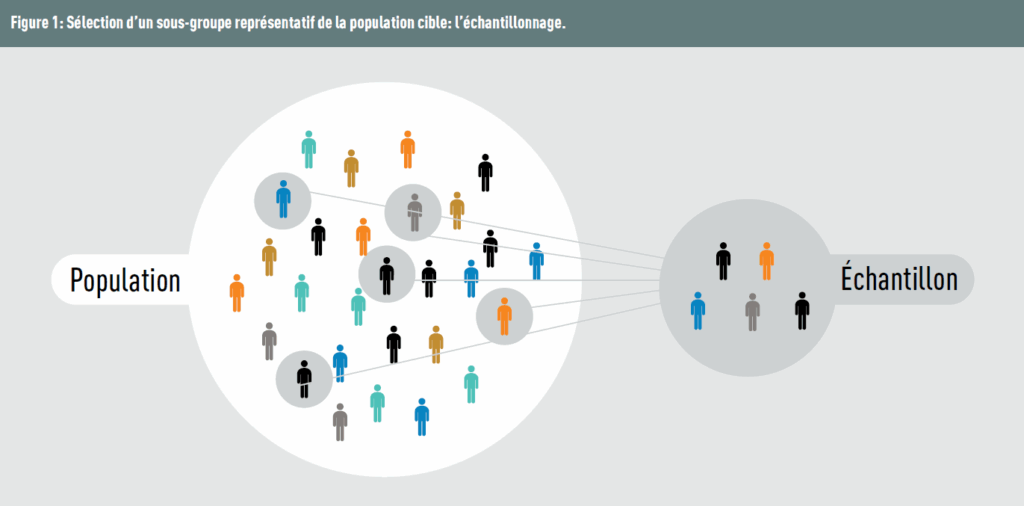
It is important to distinguish bias from random error. The latter, resulting from sampling fluctuations, affects only the precision of estimators and is distributed similarly across the study groups. Bias, on the other hand, systematically shifts the results in a specific direction. To use the dartboard analogy (Figure 2): variance represents the dispersion of the throws around the mean (the closer they are grouped, the lower the variance), while bias corresponds to the distance of these throws from the centre of the target.

Several main categories of bias can be distinguished depending on when they occur during the research process: during participant recruitment (selection bias), during data collection (information bias), or during analysis (confounding bias).
SELECTION BIAS
These biases occur during the inclusion, follow-up, or exclusion of participants, making it difficult to generalize the results to the general population. They also appear when the compared groups (cases/controls or exposed/non-exposed) differ substantially (for example, more men in one group or fewer young participants in another). Selection biases can lead to an under- or overestimation of the studied effect. Several types of such biases may be identified.
Sampling bias
This bias occurs when the sample does not reflect the target population — for example, if participants are recruited only from a single hospital rather than from diverse sources.
Nonresponse bias
This bias arises when individuals not participating in the study differ statistically from those who participate (in terms of age, gender, occupation, etc.). Refusal to continue participation may occur when questions are considered irrelevant to the study topic or when they touch on sensitive topics such as illegal practices. This bias can be assessed by comparing the characteristics of respondents and nonrespondents. It can potentially be mitigated by offering incentives (financial or otherwise), sending reminders, or using shorter questionnaires.
Volunteer bias
Also known as self-selection bias, this occurs when only volunteers participate in the study. Such individuals often have a particular interest in research and/or in their own health. Their characteristics may therefore differ from those who refuse to participate (for instance, engaging in lower-risk behaviors or having a “healthier” lifestyle or already being familiar with the questionnaires and answers). This is the counterpart of nonresponse bias.
Healthy worker bias
Also called the “healthy worker effect,” this occurs when participants are selected only among employed individuals. For example, if a company conducts a study on musculoskeletal disorders among office employees, the study will automatically exclude those on sick leave due to severe health issues. As a result, the calculated prevalence will be underestimated.
Berkson’s bias
In case-control studies, this bias (also known as admission bias) occurs when controls are selected exclusively from hospitalized patients. These controls do not represent the general population because the probability of hospitalization already depends on other diseases. In practice, individuals with multiple health problems are more likely to be hospitalized than those with a single condition, leading to distorted comparisons. To use an analogy, it’s like trying to determine who takes the train by observing only first-class passengers: one might wrongly conclude that everyone travels comfortably, without seeing those in second class or standing.
Attrition bias
Seen in longitudinal studies, attrition bias arises when participants drop out of the study. Withdrawal can result from various causes (dissatisfaction with treatment, adverse effects, etc.), but it often depends on the treatment itself. This affects the final results, as the treatment effect may appear stronger than it really is. A 2012 systematic review (1) showed that in about one out of five trials, the conclusions lost statistical significance when the outcome of interest was also observed among participants lost to follow-up. To limit this bias, an intention-to-treat analysis is strongly recommended: it includes all participants, regardless of whether they completed the study (imputing the data if it is missing at the final visit).
Neyman bias
Also known as prevalence-incidence bias, this occurs when participants are selected from prevalent (i.e. surviving) rather than incident (new) cases. Consequently, the most severe cases — those with a higher probability of death — are included, making the sample unrepresentative of the population affected by the disease.
Preventing selection bias mainly occurs during the study design stage, through a rigorous choice of data sources (registries, health service records, questionnaires, wearable devices, etc.) and recruitment methods. Once data have been collected, these biases are very difficult to correct.
INFORMATION BIAS
This bias concerns the information collected from participants and may, for example, lead to misclassification bias: individuals are incorrectly assigned to the groups “diseased / non-diseased” or “exposed / non-exposed.” Misclassification occurs when the exposure is subjective, imprecise, or when its measurement changes over time. Changes may occur in the participant’s response:
- “Social desirability bias”, originating from the participant, occurs when they provide answers that appear more “acceptable” rather than truthful. For example, they may underreport alcohol consumption or overreport physical activity.
- “Observer bias” (also known as subjectivity or assessment bias), originating from the interviewer, occurs when the interviewer knowingly or unknowingly influences the participant’s response. One way to control this bias is to blind the interviewer or physician involved in the study. When the study relies on interviewers, specific training must be provided.
- “Hawthorne effect”, which arises when participants change their behaviour or habits because they are aware of being observed.
“Recall bias”, sometimes called memory bias, is a cognitive bias. It occurs when participants cannot accurately remember events that happened to them — for example, the date a disease or symptoms occurred. Ideally, the time interval used to define exposure/disease should be short. Moreover, in studies conducted after an event (such as a hospital stay), data should be collected as soon as possible to avoid participants remembering only the “negative” aspects.
“Proxy bias” occurs when information is collected from an intermediary (a relative, family member, caregiver) rather than directly from the person concerned. The proxy has an incomplete and/or biased view of reality. This may occur in surveys on living conditions in nursing homes or studies on children’s diet (parents are not always aware of what children actually eat at school).
“Lead time bias” arises when a disease is diagnosed early, giving the illusion of a more effective treatment, even though the treatment has no effect on the disease. In short, “time is gained on diagnosis, not on life.” Figure 3 illustrates this bias.
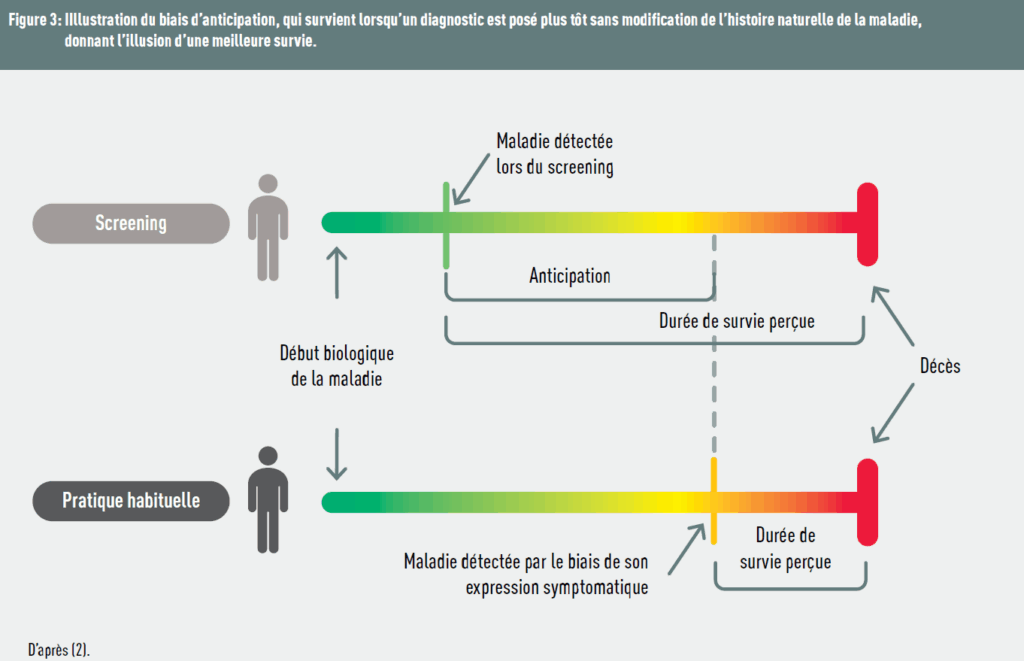
“Length time bias”, which can be confused with lead time bias, concerns the diagnosis of slow-progressing diseases: individuals with less severe disease are more likely to be detected than those with more aggressive disease, as the initial asymptomatic phase is longer for them. In this case, “screened individuals are healthier.”
In studies involving diagnostic tools, “verification bias” occurs when only part of the participants undergoes the reference gold-standard test confirming the result of the first researched test, affecting the number of false positives of the new test.
CONFOUNDING BIAS
This bias mainly occurs during statistical analysis. An external factor linked to both the exposure and the outcome can distort the interpretation of the true effect. We already discussed this in the previous article dedicated to causality.
AFTER THE STUDY
Even after a study is completed, some biases persist. The most well-known one is “publication bias”, which favours the publication of “positive” results and not releasing negative or neutral results. Another frequent bias is “interpretation bias” (or “confirmation bias”), in which results supporting the initial hypotheses or expectations are given greater weight and specifically searched for.
Take-home message
It is difficult, if not impossible, to control all sources of bias in a study. However, being aware of them and understanding their importance is essential: it allows for a better assessment of the strengths and limitations of published work, a more nuanced interpretation of findings, and ultimately strengthens the quality of data-driven clinical decisions. The study design is therefore a crucial stage for bias prevention, by implementing appropriate methods developed by methodological experts and by pre-specifying the hypotheses to be tested in a hierarchical manner. A careful examination of the Methods section of a scientific article — although sometimes perceived as complex or tedious — often reveals the presence or risk of biases that may compromise the validity of the results.
Réferences
- Akl EA, et al. BMJ 2012;344:e2809
- https://catalogofbias.org/biases/lead-time-bias/
The epidemiostatistical series published in MEDINLUX.
Related News