- Domaines || de recherche
- Recherche Translationnelle
- Médecine translationnelle transversale (MTT)
- Centre opérationnel de médecine translationnelle (TMOH)
- Service Gestion de projets cliniques (CPMO)
- Centre d'investigation clinique & épidémiologique
- Centre de recherche clinique & translationnelle du Luxembourg (LCTR)
- Biobanque intégrée du Luxembourg (IBBL)
- Disease Modeling & Screening Platform (DMSP)
- Centre du génome Luxgen
- Plateforme de recherche en pathologie (RPP)
- Projets de Recherche
et essais cliniquesSoutenez-nous - Recherche Translationnelle
Trouver chaussure à son pied : la conception des études, première étape pour réponse à sa question (de recherche)
Understanding the science of data
20 juin 2025
16minutes
Cet article a été publié dans MedinLux et fait partie d’un effort de collaboration visant à rendre les concepts statistiques et épidémiologiques accessibles aux professionnels de la santé au Luxembourg.
Chaque étude répond à une question précise. Celle-ci joue un rôle essentiel dans le choix de l’étude, qui déterminera à son tour les analyses statistiques à mener. Ces dernières sont à déterminer tôt (avant même d’avoir les données, pour éviter d’être influencées par elles, cf. article sur la valeur p). Nous allons dans cet article vous présenter les différents types d’étude, qui permettent de mieux répondre à votre question de recherche, avec leurs avantages et leurs inconvénients. Le type d’étude varie selon l’objectif de recherche: si l’on étudie la relation entre une exposition et une maladie, alors les études expérimentales seront les plus appropriées. En revanche, si l’on cherche à décrire une maladie, ou un événement en fonction d’un lieu, d’une période, ou dans une population spécifique, alors les études observationnelles seront mieux adaptées.
INTERVENIR, POUR EVALUER
Les études expérimentales, notamment les essais cliniques randomisés, ont pour but d’évaluer l’efficacité d’un nouveau traitement (dispositif ou traitement) en le comparant généralement à un placebo ou à une intervention de référence, en allouant les participants aux interventions de manière aléatoire (randomisation).
L’une des caractéristiques de ces études est la répartition des participants. Selon le type, l’attribution des traitements est différente. De nombreux schémas existent: le plus classique est l’étude en groupes parallèles. Les participants sont assignés aléatoirement à un groupe ou à un autre, parfois en s’assurant que les caractéristiques des groupes restent identiques entre les groupes (par exemple, un âge moyen identique, la même proportion d’hommes et de femmes, la même répartition de sévérité de la maladie…). Les groupes sont suivis simultanément et de manière indépendante.
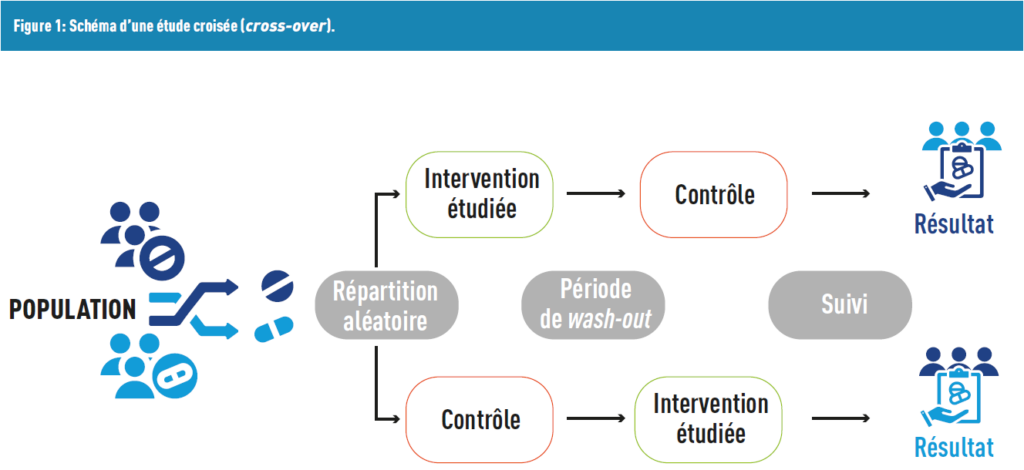
Un autre type de schéma correspond aux études croisées (cross-over), où chaque participant devient son propre contrôle. Ainsi, dans ce type d’étude, les participants reçoivent un traitement, puis s’ensuit une période de sevrage (wash-out), pendant laquelle plus aucun traitement n’est pris, pour estomper les effets du premier traitement. Enfin, chaque participant reçoit l’autre traitement qu’il/elle n’a pas eu lors de la première période (Figure 1).
Cette liste n’est pas exhaustive : d’autres approches innovantes complexes existent comme les études basket, umbrella, adaptive ou platform. Leur description sort cependant du cadre de cet article.
L’attribution des groupes peut se faire en simple aveugle (seuls les participants ne savent pas s’ils prennent le placebo/traitement de référence ou le nouveau traitement), ou en double aveugle (les participants et le personnel soignant n’ont aucune information sur le traitement). Cela limite l’effet placebo, spécifié comme une amélioration (ou détérioration) perçue par le participant, sans prise de principes actifs dans son traitement.
Les essais cliniques randomisés sont considérés comme la référence en terme de preuve et de causalité, sachant que de nombreux facteurs sont contrôlés. Néanmoins, ce type de recherche est très demandeur en temps et en budget.
REMARQUE DE LA STATISTICIENNE
Les données peuvent être analysées en :
– intention de traiter (intention-to-treat, ITT) : les participants randomisés sont inclus même s’ils n’ont pas entièrement suivi le traitement initialement prévu. L’analyse ITT vise à éviter les biais pouvant survenir dans la recherche interventionnelle, tels que l’attrition non aléatoire des participants ou les croisements entre les groupes de traitement. Cette pratique est recommandée par le Consolidated Standards of Reporting Trials (CONSORT). Toutefois, l’une des critiques de cette analyse est qu’elle est conservatrice, et donc plus exposée à un risque d’erreur de type II (cf. article sur la valeur p).
– per protocole : les participants qui ont dévié du protocole sont exclus. L’effet maximal du traitement est estimé. Du fait d’abandon (pour inefficacité, effets secondaires, …), le nombre total de participants se retrouve plus bas que prévu, ayant pour conséquence une puissance statistique plus faible. Un calcul d’échantillon est donc nécessaire pour pallier ce problème. Les bénéfices de la randomisation sont perdus et les groupes risquent d’être déséquilibrés. De plus, cela ne correspond pas aux conditions de la vie réelle, où les patients ne suivent pas leur prescription à la lettre.
REGARDER, POUR MIEUX COMPRENDRE
Comme décrit précédemment, les études observationnelles ont comme principal attribut de ne pas intervenir activement sur la population étudiée. Elles s’intéressent à l’effet d’un facteur de risque, d’un test diagnostique, d’un traitement, sans avoir d’effet sur l’exposition. Elles sont décomposées en deux catégories : les études descriptives et les études étiologiques.
AVOIR UNE IMAGE GENERALE
Dans les études descriptives, l’objectif est de décrire des phénomènes de santé, au sein d’une population. Ces études se concentrent sur la description des tendances et des caractéristiques de la population étudiée. Toutefois, à partir de ce type d’étude, il n’est pas possible d’établir une relation de cause à effet, ou d’expliquer les raisons du phénomène. Un exemple simple est l’étude du nombre de cas de grippes lors de l’hiver 2023-24, au Luxembourg.
Parmi les études descriptives, l’étude transversale (cross-sectional en anglais) analyse une ou plusieurs populations à un moment donné. Cette étude permet d’obtenir une prévalence, c’est-à-dire le rapport entre le nombre de personnes ayant une maladie donnée et le nombre total de personnes, souvent exprimé pour 10 000 ou 100 000 personnes, sans faire la distinction entre les nouveaux cas et les anciens cas. L’échantillon doit être représentatif de la population cible, afin d’obtenir une estimation non biaisée de la prévalence. Pour imager, il s’agit d’une photographie faite sur la population observée, comme par exemple l’European Health Interview Survey (EHIS), réalisée par la Commission Européenne [1].
Un autre exemple est l’étude écologique qui a un cadre plus large. En effet, les unités d’analyses sont des groupes (villes, régions, ou pays), alors que dans les études précédentes, l’individu est au centre de l’analyse, même s’il fait partie d’un groupe. Dans une étude écologique, les données sont agrégées et proviennent d’autres sources, de telle manière qu’aucune liaison avec les individus n’est disponible. Ce type d’étude peut être mené facilement, rapidement et pour un faible coût, en utilisant des données généralement déjà disponibles. I a pour but de « défricher le terrain » pour des études de cohorte ou de cas-témoin ultérieures, moins sujettes aux biais, lorsqu’elle débusque des relations intéressantes. La première dans l’histoire a été faite par John Snow sur l’épidémie de choléra à Londres, où il reportait les cas par quartier. Il devint un précurseur de l’épidémiologie, avec la création de certains concepts dont l’incidence (le nombre de nouveaux cas d’une maladie sur une période donnée).
COMPARER PLUSIEURS GROUPES
Les études étiologiques ont pour but de déterminer des liens entre des différents facteurs (environnementaux, génétiques, comportementaux) et l’apparition d’une maladie, par exemple. Contrairement aux études interventionnelles, le contrôle de certains facteurs n’est pas faisable. L’une des plus grandes limitations des études observationnelles est la présence de biais qui sont difficiles à appréhender. Le plus notable est lorsque la population étudiée n’est pas représentative de la population cible, introduisant ainsi un biais de sélection. Toutefois, la liste est assez longue (confusion, mesure, information…) et ils seront expliqués dans un prochain article !
ETUDES CAS-TEMOIN
Elles distinguent deux groupes d’individus : le premier ayant le problème de santé (cas), alors que le second, qui n’a pas le problème de santé, est appelé témoin (ou control en anglais). Les individus du groupe contrôle ont la particularité d’avoir les mêmes caractéristiques (âge, sexe, …) avec ceux du groupe de patients atteints par la maladie. La variabilité individuelle est diminuée en raison de l’appariement des groupes. Ce design est courant dans le cas d’une maladie rare.
ETUDE DE COHORTE
L’étude de cohorte est adaptée lorsque les chercheurs s’intéressent à une population définie, qui a plusieurs niveaux d’exposition à des facteurs de risque, comme, par exemple, des travailleurs (population) qui utilisent (ou non) une machine émanant des gaz toxiques (facteur de risque). Ce type d’étude permet d’analyser plus facilement des maladies à incubation courte, chroniques avec plusieurs stades, et/ou qui sont relativement fréquentes. Elles peuvent être spécialisées (sur un problème spécifique, un effectif très petit, et des données très détaillées), ou alors plus générales (de grande taille, avec une couverture large de problème de santé, et des données plus approximatives). De plus, elles peuvent constituer une base pour des recherches plus approfondies, comme par exemple le projet CLINNOVA, dans lequel le LIH est impliqué [2]. Celui-ci recueille des données à travers plusieurs cohortes européennes, ayant pour but l’amélioration des traitements par l’utilisation de l’intelligence artificielle pour 3 maladies inflammatoires (de l’intestin, rhumatoïde ou la sclérose en plaques).
AVANT OU APRES L’APPARITION DE LA MALADIE ?
Une autre question à se poser est le moment où on souhaite étudier notre population : est-ce que c’est avant ou après qu’elle ne développe cette maladie ?
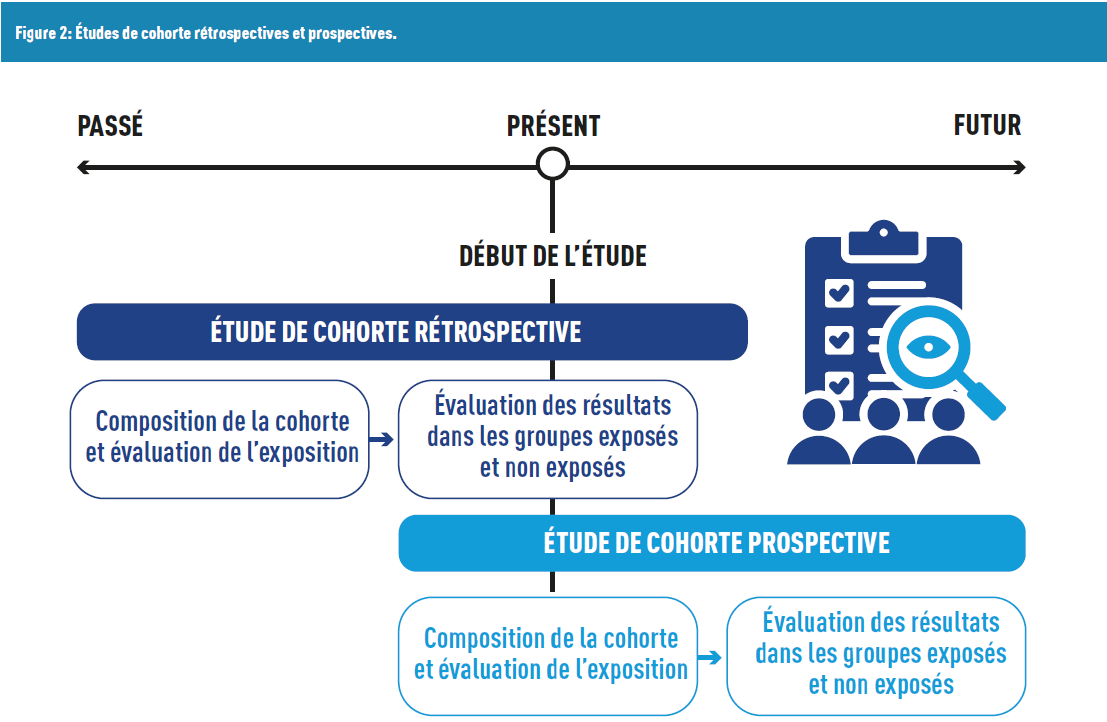
Dans le premier cas, il s’agit d’études rétrospectives : les participants ont déjà la maladie, et on « examine » le passé pour identifier des expositions, ou des facteurs de risque potentiels. L’une des limites est le biais de mémorisation : les participants peuvent avoir des difficultés à se souvenir de l’exposition. Il peut être minimisé lorsque le dossier médical est consultable et que les données contenues peuvent être intégrées (avec un consentement du participant, notamment pour respecter le règlement général sur la protection des données (RGPD)).
Le second cas correspond à des études prospectives : le but est d’identifier des facteurs de risque pour prédire l’apparition (ou non) de la maladie. Elles ont une temporalité dans le futur. Elles sont plus coûteuses, du fait de leur durée (dans le cas où on étudie le participant jusqu’à ce qu’il ait la maladie).
MESURER LE MÊME INDIVIDU PLUSIEURS FOIS OU DIFFERENTS INDIVIDUS UNE SEULE FOIS ?
Parmi les études observationnelles, les études longitudinales (aussi appelé études de panel) servent à suivre la même population au cours du temps : cela peut être sur plusieurs jours, mois, années, ou décennies, selon les facteurs de risque qui intéressent. Le but est de détecter des changements chez les participants, d’examiner l’association entre l’exposition connue ou suspectée d’une maladie et l’apparition de cette dernière. L’une des premières (et des plus connues) est l’étude de Framingham, qui a commencé en 1948 aux Etats-Unis, avec pour objectif l’analyse des maladies cardiovasculaires et de leurs déterminants.
Attention, il ne faut confondre les données issues de données longitudinales, avec des données d’études transversales répétées. En effet, ces dernières font des mesures répétées sur des individus différents, alors que les premières suivent les mêmes individus à travers le temps
COMMENT EVALUER LES ETUDES ?
En pratique clinique, les choix peuvent s’opérer selon plusieurs pensées (qui ont été définies par Isaacs et Fitzgerald [3]):
- La tradition : vous avez toujours donné ce traitement aux patients souffrant de cette pathologie,
- L’expérience : depuis que vos débuts de practicien(ne), vous vous êtes rendu compte que ce traitement fonctionnait mieux,
- L’opinion d’expert (eminence based medicine) : vous avez consulté un confrère spécialisé et/ou reconnu dans un domaine pour une opinion/expertise et vous vous fiez à ses conseils,
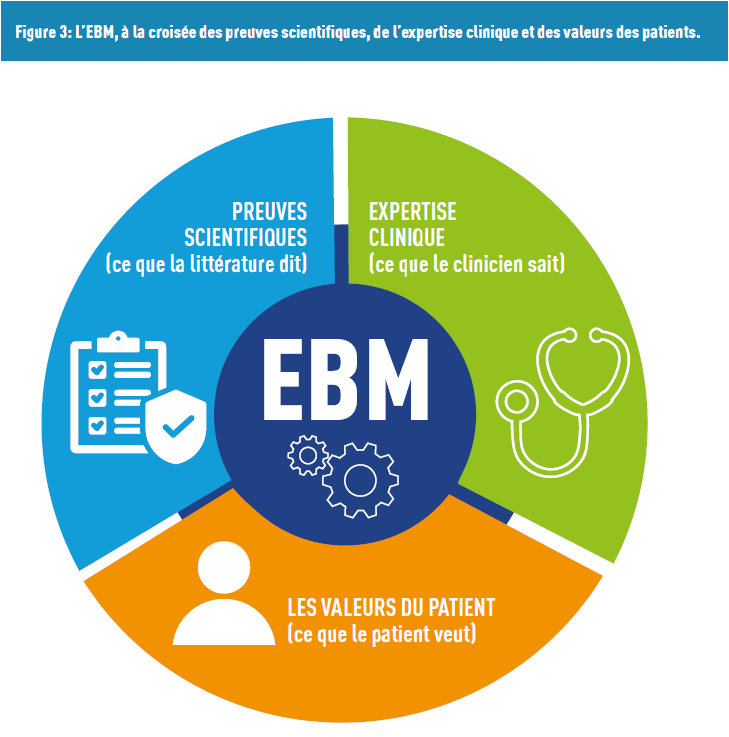
Ces approches sont souvent mises en opposition à la médecine fondée sur les faits (Evidence-Based medicine, EBM). Ce concept, né dans les années 1950, correspond à un mélange de principes et de méthodes, en tenant compte des connaissances du médecin, des avancées de la recherche et des valeurs du patient (Figure 3).
Dans ce contexte, les informations provenant de la littérature scientifique n’ont pas le même niveau d’évidence. Plusieurs démarches permettent de les évaluer.
Premièrement, l’outil GRADE [4] (Grading of Recommendations Assessment, Development and Evaluation), utilisé dans plus de 100 organisations à travers le monde, permet d’évaluer la qualité des études, et d’effectuer des recommandations. Le niveau de certitude varie de « très bas » (l’effet réel est probablement très différent de l’effet estimé) à « élevé » (le niveau de confiance des auteurs est élevé concernant l’exactitude de l’effet estimé par rapport à l’effet réel). Cette échelle se base sur plusieurs critères comme le risque de biais, l’imprécision ou le manque de cohérence (avec des études existantes).
Deuxièmement, des niveaux d’évidence ont été créés, et sont supportés par la communauté scientifique ainsi que par de nombreuses instances (Organisation Mondiale de la Santé, Haute Autorité de Santé…). Le niveau le plus bas est l’opinion d’un groupe d’experts, suivi par les séries de cas (ou rapports de cas), étant donné qu’il ne concerne qu’un petit nombre de personnes, et que leurs conclusions sont difficilement extrapolables à une population plus grande. A l’opposé, le niveau le plus élevé concerne les méta-analyses (méthode de recherche statistique qui combine les analyses de plusieurs études, ayant le même sujet). La première étape de cette méthode consiste à établir une revue de littérature systématique, avec des critères définis en amont, puis d’extraire l’information de chacun des articles choisis comme pertinents. La dernière étape est d’obtenir une estimation globale de l’effet, tenant compte de l’hétérogénéité des études, souvent représentée par des graphiques en forêt (forest plot)(Figure 4).
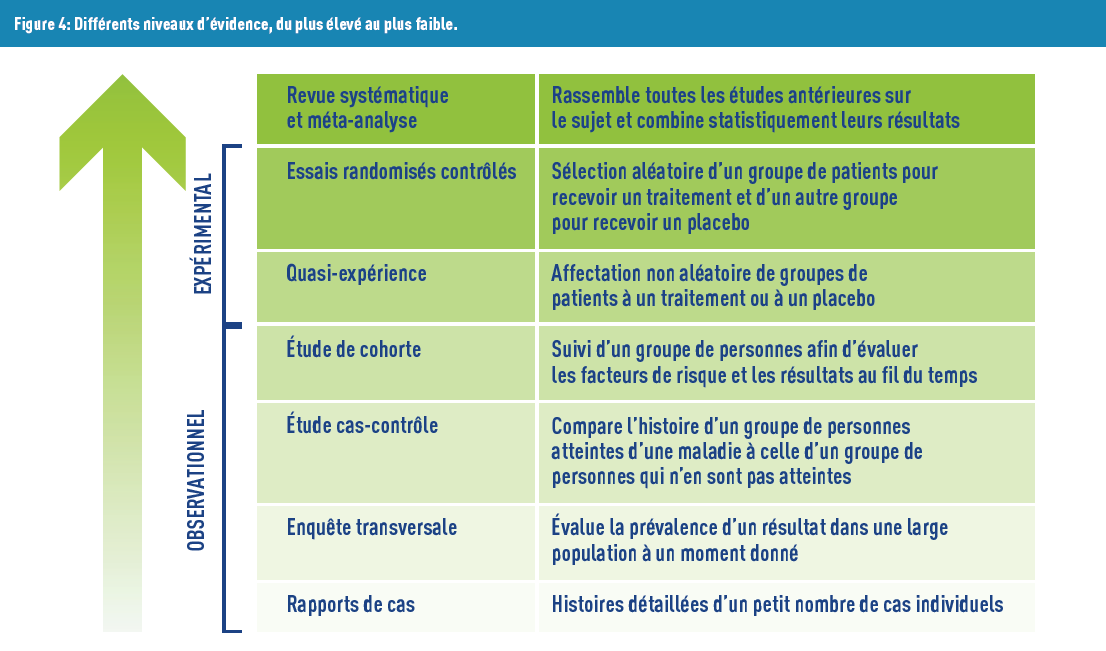
Cependant, chaque outil a aussi son lot de critiques. D’une part, il peut y avoir des biais de publication, où seules les études avec des résultats « intéressants » ont été publiées et sont donc accessibles. Ceci a un impact dans les méta-analyses (entre autres), en raison de la combinaison d’études !
D’autre part, l’essai clinique est considéré comme la référence en terme de preuve. Bien qu’il concerne des patients avec une seule pathologie et très sélectionnés, l’extrapolation des résultats peut être difficile dans des populations différentes ! Cette problématique se pose pour des patients âgés par exemple, qui ne sont pas assez représentés dans les études. Toutefois des essais gériatriques sont de plus en plus mis en place afin de tester les traitements en concomitance avec des multimorbidités dont souffrent ces patients
IL N’Y A PAS QUE LES CHIFFRES
Aussi, ce récapitulatif ne tient compte que d’études où nous quantifions les phénomènes, bien qu’il existe également des études qualitatives, généralement basées sur des groupes de discussions ou des entretiens individuels, impliquant un nombre limité de participants (méthode DELPHI). Ceci permet de comprendre les expériences, les perceptions et le comportement de ces derniers. Cela a comme avantages d’être flexible et de générer des nouvelles idées. A l’inverse, les informations sont subjectives, avec des petits échantillons (difficile de généraliser à des populations plus grandes), et donc non reproductibles.
Une fois que vous avez sélectionné le type d’étude qui répond à votre question de recherche, le calcul de la taille d’échantillon (ou de puissance) permet d’avoir assez de « force » pour valider votre étude (cf. article précédent sur la valeur p). Dans le prochain article, nous explorons les concepts d’association et de causalité. N’hésitez pas à nous faire parvenir vos questions sur des thématiques épidémiologiques ou statistiques particulières. Nous y répondrons ultérieurement.
TAKE HOME MESSAGE
Le tableau ci-dessous résume les différentes notions expliquées dans l’article.
| QUESTION POSEE | TYPE D’ETUDE |
|---|---|
| Est-ce que le test X permet de détecter plus facilement un cancer du poumon que le test Y ? | Essai randomisé |
| Quelle est l’incidence du cancer du poumon au Luxembourg ? | Etude de cohorte |
| Quelle est la prévalence du cancer du poumon chez les fumeurs ? | Etude transversale |
| Est-ce que les personnes exposées au tabagisme passif ont plus de chance de développer un cancer du poumon ? | Etude cas-témoin, étude de cohorte |
| Quel est le ressenti de la prise en charge des patients avec un cancer du poumon ? | Etude qualitative |
Réferences
- 1. https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Glossary:European_health_interview_survey_(EHIS)
- 2. https://www.lih.lu/fr/article/clinnova-lance-une-initiative-de-medecine-de-precision-au-coeur-de-leurope/
- 3. https://www.bmj.com/content/319/7225/1618
- 4. https://gdt.gradepro.org/app/handbook/handbook.html
The epidemiostatistical series published in MEDINLUX.
Actualités associées