Maîtriser les outils statistiques et épidémiologiques pour mieux décrypter les articles scientifiques
Comprendre la science des données
Cet article a été publié dans MedinLux et fait partie d’un effort collaboratif visant à rendre les concepts statistiques et épidémiologiques accessibles aux professionnels de santé au Luxembourg..
Le clinicien est la liaison entre le chercheur, qui produit l’information par l’intermédiaire de ses recherches, et les patients, qui souhaitent être le mieux soignés. Les informations provenant d’articles édités par des journaux scientifiques à comité de pairs ont une influence sur la pratique médicale et ce, d’autant plus qu’à l’ère de la « médecine basée sur les preuves», ce sont sur elles que s’appuient les recommandations émises par les sociétés savantes. Les informations de la littérature médicale permettent notamment au clinicien d’être au courant des dernières découvertes médicales et donc des traitements les plus performants et/ou les mieux supportés dans sa sphère d’activités. Compte tenu de ces enjeux, la lecture critique médicale apparaît fondamentale pour juger de la validité des résultats publiés (c’est-à-dire les conditions dans lesquelles ils sont vrais) et de leur pertinence pour la pratique. Cet article introduit une série de textes dont l’ambition est de donner les principales clés utiles à l’interprétation critique d’un article scientifique et de ses conclusions.
LES CARACTÉRISTIQUES DE L’INFORMATION MÉDICALE
Un processus long et complexe
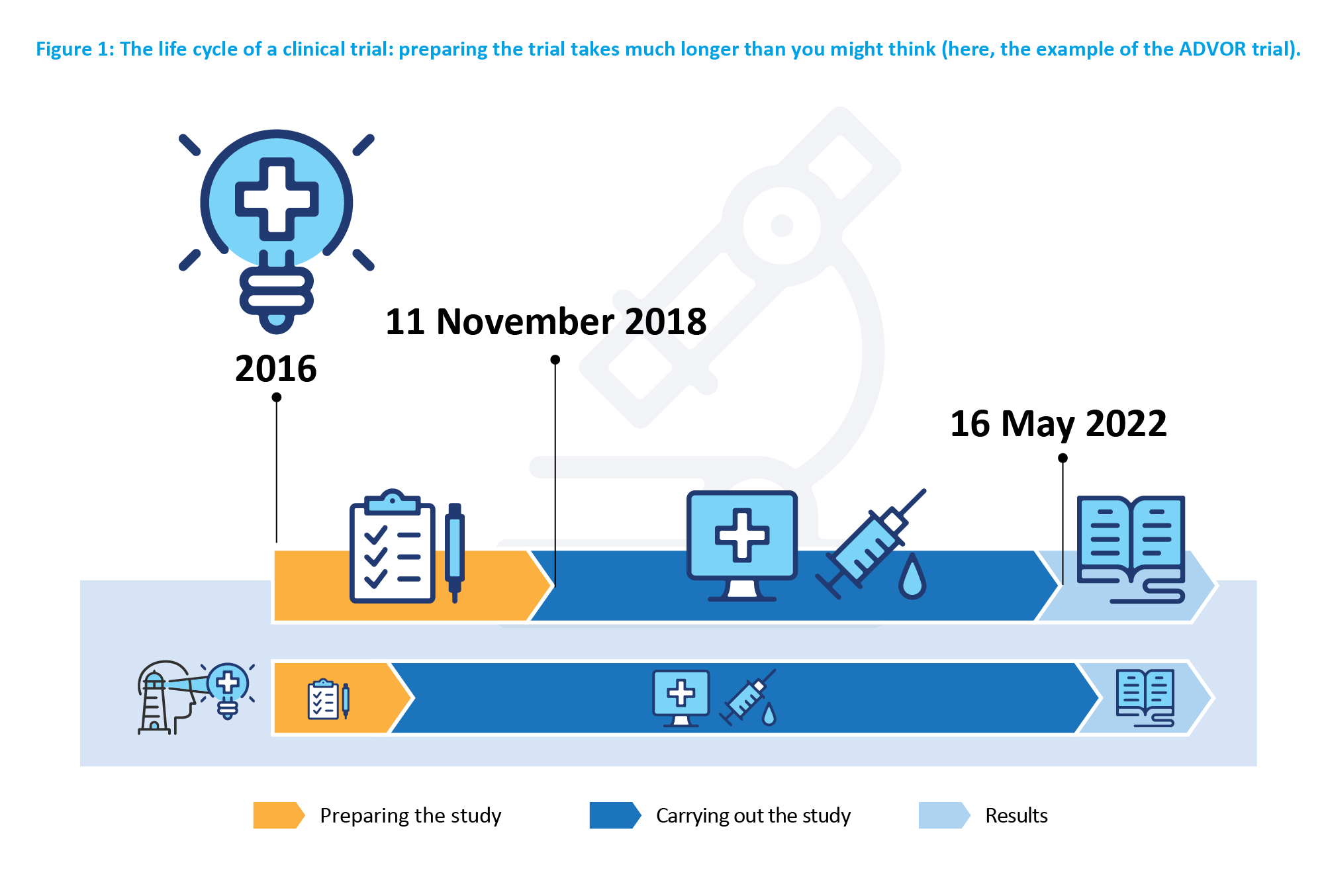
À l’heure du numérique et de l’actualité instantanée, l’information est rapide, courte et immédiate. À l’inverse, la production d’un article scientifique est l’aboutissement d’un long processus de recherche, s’étendant généralement sur plusieurs années. En effet, toute étude fait intervenir des acteurs de différents domaines et se déroule en plusieurs étapes successives: formuler la question, conceptualiser la méthode pour y répondre, rechercher les participants, collecter les données tout au long du suivi, analyser les données centralisées dans un entrepôt de données (data warehouse) et interpréter les résultats dans leur contexte (Figure 1).
De plus, les masses de données accumulées sont de plus en plus importantes dans le monde de la recherche. Leur gestion est devenue un métier à part entière: clinical data manager. Autrement appelé gestionnaire des données, son rôle est de les structurer, de vérifier leur cohérence et leur fiabilité, et de les préparer pour la partie statistique. Plus la base de données est de bonne qualité, plus l’analyse sera pertinente et précise.
Des publications foisonnantes
Des études bibliométriques récentes montrent que le nombre d’articles scientifiques publiés a augmenté de 8 à 9% par an au cours des dernières décennies (1). Par exemple, la base de données d’articles scientifiques dans le domaine médical et de la science de la vie Pubmed a publié près de 1.400.000 articles en 2022 et ceci, sans compter la «documentation grise» provenant d’autres sources (notamment issue de gouvernements, de rapports, de documents de travail…) ni, bien sûr, des études non publiées (lorsque le traitement s’avère inefficace ou la preuve statistique insuffisante, par exemple; à l’origine du biais de publication). Ainsi, ce volume d’information est difficilement accessible.
Une obsolescence rapide
Conséquence de la multiplication des publications, on observe une obsolescence accélérée des connaissances médicales.
Une qualité variable
En plus de la quantité, la qualité peut être mise à l’épreuve, même si les articles publiés sont revus par des pairs indépendants (dans le cadre de journaux scientifiques). Certaines notions sont plus complexes et nécessitent une expertise particulière. Leur mauvaise utilisation entraîne des résultats ou des interprétations erronés (voir exemple infra) qui peuvent avoir des conséquences néfastes sur la pratique clinique. Par ailleurs, les objectifs des auteurs peuvent être mal compris et, in fine, mal retranscrits. Heureusement, de nombreuses lignes directives existent, permettant ainsi d’avoir un cadre pour la recherche et sa qualité (2). C’est pourquoi une lecture critique de la documentation scientifique, en relativisant l’information, est fondamentale.
L’enjeu de la préservation de la vie privée
L’évaluation de l’information inclut aussi le questionnement sur la source et la gestion des données. Cela vaut de manière générale, mais plus encore pour les informations médicales, qui sont particulièrement sensibles. Aussi, la gestion des données privées, conditionnée par le Règlement Général sur la Protection des Données (RGPD), est une étape fondamentale dans une étude. En effet, la collecte, le stockage et la sécurisation des données sont des paramètres non négligeables pour le respect de l’intégrité des données, mais aussi de la vie privée des participants. Des outils informatiques appropriés sont importants pour garantir les données et leur exploitation.
Des informations mal interprétées, voire détournées
La crise du Covid-19 a révélé un certain intérêt de la population générale pour l’épidémiologie (3) et les statistiques, malgré un défaut de connaissances nécessaires pour la compréhension de ces concepts. Ainsi, bien que cette attention soit bénéfique à terme, des messages incomplets ou erronés ont été véhiculés (4), parfois volontairement. Tout le monde a en mémoire ce climat délétère d’ultracrépidarianisme et de «complotisme». Dans ce contexte, le terme «infodémie» (ou «infodémiologie ») a été créé par plusieurs organismes, dont l’Organisation Mondiale de la Santé (5), avec l’idée de mettre en avant l’importance de détecter les informations fausses ou trompeuses.
La lecture critique médicale apparaît fondamentale pour juger de la validité des résultats publiés et leur pertinence pour la pratique.
Deux exemples
De ce qui précède, on peut conclure à la masse et à la complexité de l’information médicale. Parmi les écueils possibles, on retrouve l’interprétation incorrecte des résultats (premier exemple) et les recherches affectées de certains biais, volontairement (second exemple) ou pas.
1er exemple
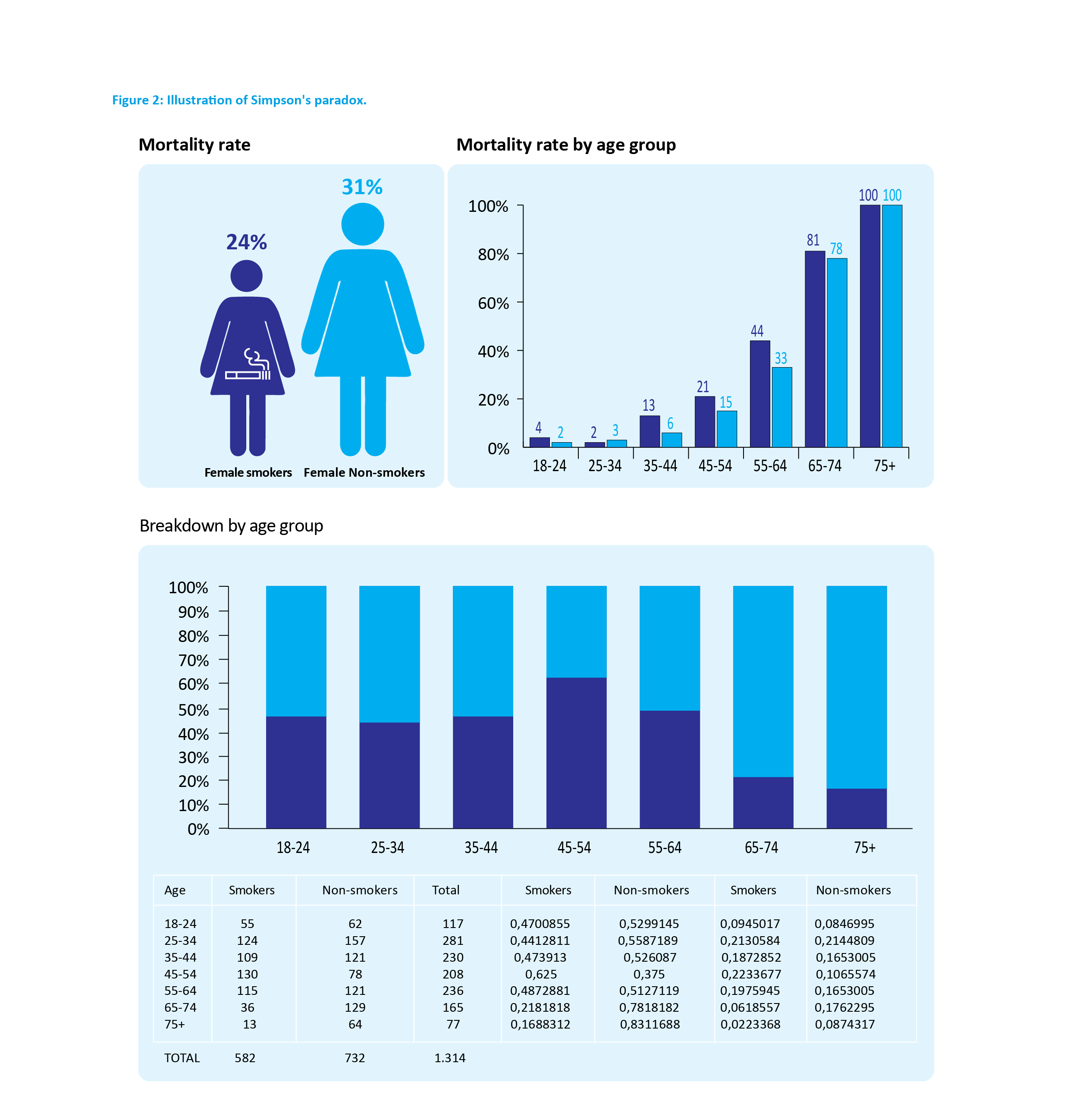
L’utilisation de statistiques peut être la source de résultats complètement contre-intuitifs, bien que démontrés rigoureusement. C’est ce que l’on appelle des paradoxes, c’est-à-dire des résultats qui ne sont pas faux mais incompatibles avec notre intuition. L’un des paradoxes statistiques les plus interpellants est celui qu’Edward Simpson a décrit en 1951, qui stipule qu’il est possible qu’un même phénomène ait lieu à l’intérieur de différents groupes, mais que ce dernier s’inverse lorsque les groupes sont rassemblés (6). Il a été observé dans de nombreuses études, dont une sur la consommation de cigarettes (7), dans laquelle des femmes ont été suivies pendant 20 ans dans le but de comparer le taux de mortalité entre les fumeuses et les non-fumeuses. Un des résultats – surprenant – était que le dernier était plus faible chez les fumeuses (24%) que chez les non-fumeuses (31%), ce qui permettait en première analyse de conclure à un effet protecteur de la cigarette… Toutefois, lorsque l’on analyse plus en détails les données et que l’on décompose les taux de mortalité selon les groupes d’âge, la mortalité est toujours supérieure chez les fumeuses. Ces conclusions contradictoires s’expliquent par le fait que le groupe des non-fumeuses était composé de femmes plus âgées et, par conséquent, présentant un taux de mortalité plus élevé (Figure 2)!
2nd Example
Un autre exemple marquant est celui du vaccin ROR (rougeole, oreillons, rubéole). En 1998, la revue The Lancet publia un article faisant le lien entre le vaccin combiné ROR et l’autisme. Le Dr Andrew Wakefield et 12 autres coauteurs avaient trouvé une association entre la perte de capacités acquises (dont le langage) et l’administration de ce vaccin. Plusieurs années ont été nécessaires avant de démontrer que l’information était fausse et que l’article soit rétracté (8). Entre-temps, les résultats de l’étude avaient été largement médiatisés et ont généré une certaine défiance vis-à-vis de ce vaccin (9) et de la vaccination en général. L’Agence de protection de la santé britannique a attribué l’importante épidémie de rougeole qui frappa le pays en 2008-2009 à une baisse concomitante du nombre d’enfants ayant reçu le vaccin ROR (8).
Plusieurs irrégularités ont été relevées dans la publication rétractée. Tout d’abord, certaines des recherches de Wakefield étaient financées par des avocats représentant des parents impliqués dans des procès contre des fabricants de vaccins. Ensuite, les cas de l’étude ne faisaient pas partie d’une série consécutive, comme annoncé, mais avaient été sélectionnés (biais de sélection). De plus, le nombre d’observations était très faible (un échantillon total de 12 enfants) et n’était pas suffisant pour démontrer un réel lien (problème de puissance des tests).
Pour la petite histoire, Andrew Wakefield a été radié de l’Ordre des Médecins en 2010 et est devenu un pilier du mouvement antivax international.
Ces exemples montrent le potentiel de manipulation qui peut se cacher dans une étude: une information fausse devient <réelle»!
Des études bibliométriques récentes montrent que le nombre d’articles scientifiques publiés a augmenté de 8 à 9% par an au cours des dernières décennies.
Une caisse à outils, pour faire parler les données
La statistique peut être perçue comme un ensemble d’outils pour faire «parler» les données. Le statisticien (ou data scientist) détermine l’outil le plus approprié pour répondre à chaque problème/question. Un outil inadapté donnera des résultats, mais qui ne seront pas les plus justes et, dans le pire des cas, biaisés, voire faux. Pour illustrer ceci, imaginons que vous deviez resserrer une vis sur une machine. L’ustensile dont vous auriez besoin serait un tournevis, mais il peut arriver que vous vous trompiez sur la forme ou sur la taille de l’embout. Dans le même ordre d’idées, au sein des statistiques descriptives, une moyenne ne peut être calculée sur des caractéristiques catégorielles comme le statut tabagique ou le sexe.
Il faut également être outillé pour lire et comprendre les articles scientifiques, leurs spécificités, leurs forces et leurs faiblesses. Le feuilleton épidémio-statistique que ce premier article initie a précisément l’ambition de délivrer l’essentiel des outils utiles.
Ainsi, dans les prochains numéros, plusieurs sujets seront traités pour développer et affiner vos connaissances des statistiques: les probabilités conditionnelles, l’interprétation de la p-value (ou du «p») à partir de la théorie des tests, les types d’étude (avec leurs avantage et inconvénients) – épidémiologiques et les essais cliniques –, le calcul de taille d’échantillon et de puissance, les biais, les mesures d’association et de causalité, les outils diagnostiques et les revues systématiques avec ou sans méta-analyse de la littérature… Chaque fois, nous nous appuierons sur des exemples tirés de la littérature récente.
Ainsi, à terme, vous ne vous emmêlerez plus les pinceaux entre signification statistique et pertinence clinique, entre les risques relatifs et les risques absolus, vous connaîtrez les limites des études rétrospectives ou de non-infériorité, vous apprendrez à repérer les biais présents dans un protocole, vous connaîtrez les avantages des analyses multivariées, les courbes ROC n’auront plus (beaucoup) de secrets pour vous, et bien d’autres choses encore… Il y aura bien sûr un prix à payer ou plutôt une habitude à prendre: jeter un œil à la section «matériel et méthodes» … Et nous lire.
N’hésitez pas à nous faire parvenir vos questions sur des thématiques particulières. Nous y répondrons ultérieurement.
Références
- Landhuis E. Scientific literature: Information overload. Nature 2016;535:457-8.
- https://www.equator-network.org/
- https://www.sciencepresse.qc.ca/actualite/2021/06/15/covidepidemiologie-projecteurs
- https://www.pasteur.fr/fr/journal-recherche/actualites/coronavirusattention-aux-fausses-informations-covid-19-circulant-reseauxsociaux
- https://www.who.int/fr/news-room/spotlight/let-s-flatten-theinfodemic-curve
- Berger Q, Caravenna F. Le paradoxe de Simpson illustré par des données de vaccination contre le Covid-19. www. theconversation.com
- Appleton DR, French JM, Vanderpump MPJ. Ignoring a covariate: An example of Simpson’s paradox. The American Statistician
1996;50(4):340-1. - https://www.cmaj.ca/content/182/4/E199
- https://www.bbc.com/afrique/monde-59868419
The epidemiostatistical series published in MEDINLUX.
Actualités associées